
How I Keep Accidentally Building Tools
On the shortening distance between "I wish this existed" and "I guess I'll build it"
I keep building tools I didn't plan to build. Some are side-projects: A better public broadcast archive, an Arabic learning app, an analysis of local Green-party political programs. And many are tools that help me at work, like a design mockup generator that started as "show me four options." And most recently, a code review tool that started as "can you just explain what this colleague changed and why."
Each time, the same thing happens: I ask an AI for help understanding something, the result is good enough to save, the saved version hits a wall, and before I know it I'm two weeks into building a real application. It's what happens when the distance between "I wish this existed" and "I guess I'll build it" gets short enough that you cross it almost by accident.
It’s like training a muscle, the opposite of learned helplessness – the more often you see a friction or a gap, and think to yourself “I could build that, I could fix that”, and actually experience success, you become more ambitious, less “patient”. Things that would have been a $100 million startup a few years ago is now an afternoon project. Here’s the story of one of these.
In software development, we practice code review. For vibe coding, we don’t care much about reading the code, but for a professional product with users, real data, security etc, we still need to read and be personally and collectively responsible for all code changes, regardless of how the code was generated. But with Claude Code and other tools, we’re all generating more code than ever, tackling more ambitious projects. And thus, PR-review becomes a bottleneck, and you start dreading receiving the 35-file complete rewrite of a complex algorithm, which you need to deeply understand in order to sign-off on. If Claude helped us generate the code, can it help us understand it as well?
We generate faster than we comprehend
An old concept for software engineers is “tech debt”, it’s the debt that you accumulate as you take shortcuts, things where you have to move fast, “I’ll clean it up later”. In the same way as few companies can exist without financial debt (not very ambitious ones!), there’s a fine balance between drowning in tech debt on one side, and being overly cautious and over-engineering up front on the other.
But AI has made the generation side dramatically faster without doing much for the comprehension side. Margaret-Anne Storey (via Simon Willison) calls this "cognitive debt". Addy Osmani calls it "comprehension debt". This is the sense of gradually losing the deep understanding and intuition of your code base, how it is organized and how it works. And just like tech debt, if not managed, it keeps growing exponentially. So just like we keep iterating on how we can set up systems and models to generate high quality code faster, we need to iterate on how to maintain and improve our understanding of the code as a team.
"This is awesome — save this as a skill"
Like a lot of my projects, this one started by accident.
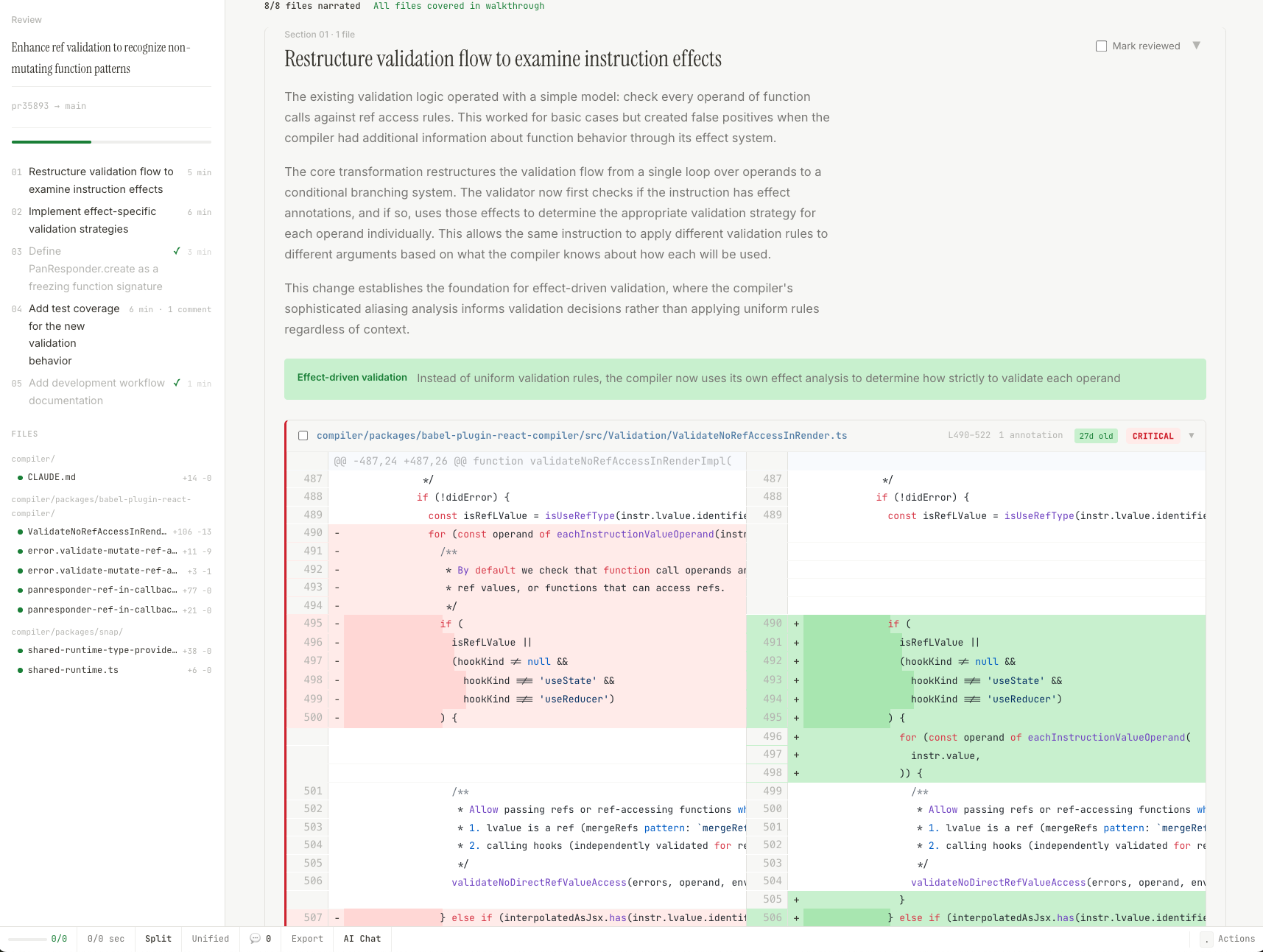
I was reviewing a colleague's pull request — introducing the concept of external integrations (like Github), changes spread across a bunch of architectural layers, implications not just for the current integration but for all future integrations. On a whim, I asked Claude Code to generate a detailed visual walkthrough of the PR: what changed, why, how the pieces connect. It produced a self-contained HTML page — ten sections, architecture diagrams, annotated code. Basically a teaching document about the PR.
My immediate reaction: "This is awesome, can you save how to generate this as a skill?"
What’s a skill? It’s basically a reusable prompt or recipe that you can ask Claude to use (or it will trigger automatically if you use certain words). It’s like cooking something by mixing things until they taste well, and then writing down the exact measurements to make it repeatable. So now I had a pr-walkthrough skill, and I used it whenever I encountered a meaty, complex PR. Over the next two weeks I generated walkthroughs for maybe a dozen PRs across different projects — CRDT syncing algorithms, semantic search, image generation pipelines. Each time, the narrative made the code legible in a completely different way than just reading the raw diff, or even the short PR description that accompanied the feature.
But something was missing. I would read the walkthrough, grok the big concepts, but then I’d switch tabs to the actual GitHub PR view to do my review, and I’d be right back staring at thirty files in alphabetical order. All that understanding I’d just built — the logical grouping, the “read this first, then this makes sense” sequencing — was stuck in a separate tab. I couldn’t post review comments from the walkthrough. I couldn’t track which files I’d actually looked at. Understanding and reviewing were two completely separate activities.
“Why hasn’t Github built this narrative explanation into its diff review?”
So of course I went looking: has anyone actually built this?
No. There were tools that generated AI narratives about PRs (CodeRabbit, GitHub Copilot's PR summaries) — but they produce a separate comment, disconnected from the diff itself. And there were good diff viewers — but with no narrative structure. Nobody had put the AI-generated narrative inside an interactive diff viewer. Which, I mean, seemed like the obvious thing to do?
The research detour
I have a PhD in education and a possibly unhealthy habit of wanting to read the literature before building anything. What does cognitive science actually say about how people process complex documents? How do humans read diffs? Has anyone studied what makes code review effective or ineffective?
In my pre-AI life I would have spent a week on this and probably settled for whatever I found on the first two pages of Google Scholar. Instead, I ran a "research swarm" — eight parallel AI agents, each searching a different domain: code review interfaces, diff visualization, narrative comprehension, cognitive load, annotation systems, and so on. In a little while, it had skimmed through maybe 180 paper summaries. Most were irrelevant or redundant — the agents cast a wide net, not a deep one. But buried in the pile were three or four findings that helped design a better tool (as well as some libraries that helped with the actual implementation).


The findings that actually mattered
Most of what the research swarm turned up confirmed things I already suspected. But three findings changed how I built the tool — and each one is less comfortable than the last.
The easy win: order matters. A 2022 study found that reviewers had 64% lower odds of catching a problem in the last file they were shown compared to the first. And the standard tools show files alphabetically/by tree. This is the simplest kind of design insight: the presentation order is actively sabotaging your attention, and nobody has fixed it. So the tool has the AI reorder material into a logical reading sequence, important things first. If you’ve ever read a long report and noticed your attention was sharpest on the first few pages and haziest on the last — same phenomenon, and probably the same missed fix.
The harder problem: you stop looking after you find something. There’s a phenomenon in radiology called “satisfaction of search” — once a radiologist spots one abnormality, they’re significantly more likely to miss a second. The same pattern shows up in code review, and probably in any task where you’re scanning complex material for problems. You catch a bug in section three, and sections eight through fourteen get a lighter read than they deserve.
I don’t think any interface fully solves this — it’s a cognitive bias, not a UI problem. But the tool at least makes incompleteness visible. You see “3/14 sections reviewed” at all times. Critical sections stay flagged in red until you’ve explicitly marked them. Every file in the PR is surfaced whether the narrative covers it or not. You can still rush through the last few sections, but you have to consciously choose to.
The finding that made me nervous about the whole project. One study showed that narrative walkthroughs significantly improve comprehension accuracy. Great. That’s the entire premise validated. But a different study found that people working with AI-generated narratives report less cognitive effort, and the researchers had a name for it: “illusion of comprehensive understanding.” The narrative genuinely helps you understand — and simultaneously makes you overconfident about how much you’ve understood.
I keep coming back to this because it’s not really about code. It’s the same problem with every AI-generated summary — of meeting notes, research papers, news articles, patient charts. The summary helps. The summary also quietly replaces the work of actually engaging with the material. You read the summary and feel like you read the thing. I don’t think anyone has figured out how to handle this well, and I suspect it’s going to be one of the defining design problems of the next few years.
The goal has to be the AI bridging your understanding, so you can tackle the real content (similar to what I’m doing with my Arabic tutor, and my “book companion” experiments), but it’s an obvious tension to keep in mind. For this tool, it meant one firm design constraint: it structures your reading, but it doesn’t let you skip anything. Every file shows up. There’s a progress tracker. You can’t submit your review without having at least seen everything. The AI is a guide, not a substitute.
Building the thing
The first working version was built during an overnight unsupervised marathon where Claude Code iterated (using agent-browser to test interactively, writing test cases for itself, using a swarm of agents).
Then I had something that was actually functional, and I could use! Hooked right up to Github, syncing all of the comments, letting me comment directly on code, chat with an AI in-context, read through the narrative and review the code in a meaningful order (with all the insubstantial edits collected at the end), and approve the PR. Reading the summary isn’t a warm up to actually reviewing the code, instead, when you are done reading the summary, you have actually finished reviewing the code!
The pattern
I mentioned this at the top but I want to dwell on it, because I think it's the most generalizable part of this story.
Prompt → skill → tool. You ask for help once, maybe iterate a bit. It's useful, so you save the approach. The saved approach is useful enough that you hit its limits. So you build a proper thing. Each step because the previous one wasn't quite enough.
I've now done this a number of times — with the code review tool, with a language learning app, and with a design mockup generator. Each time I didn't set out to build a tool. I just kept pulling the thread.
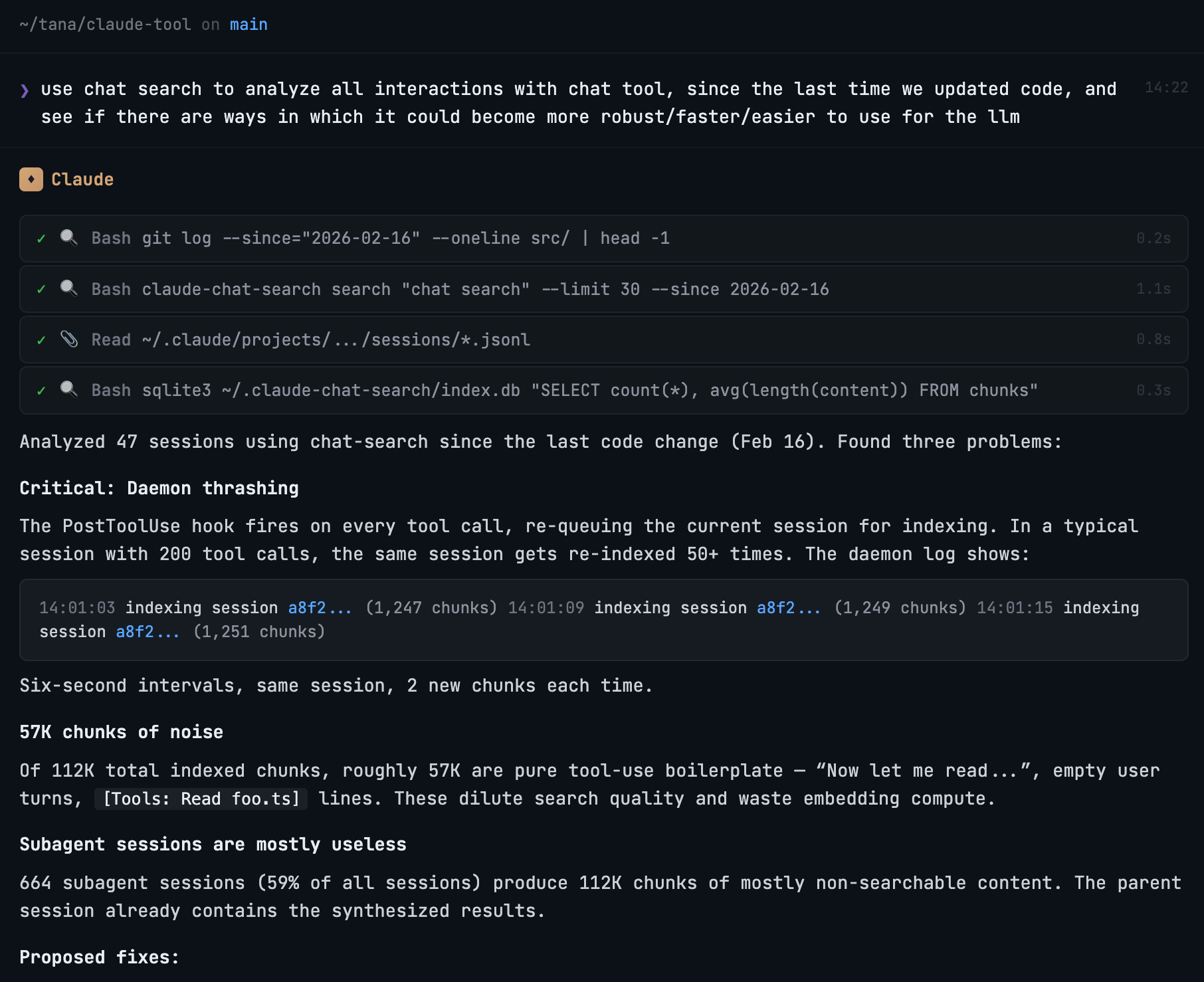
And once you have the skill, or the tool, you interact with it, and you track all interactions. All Claude chats are stored automatically, and you can ask Claude to analyze them. All tools get full analytics built-in. After a while you ask “Look at my usage patterns, look at the errors, the times it took too long to respond or couldn’t find data – how can we improve it”. And you iterate.
What's next: explanations that know what you know
There's something else I've been working on separately that I haven't connected to the PR review tool yet, but I keep thinking about it.
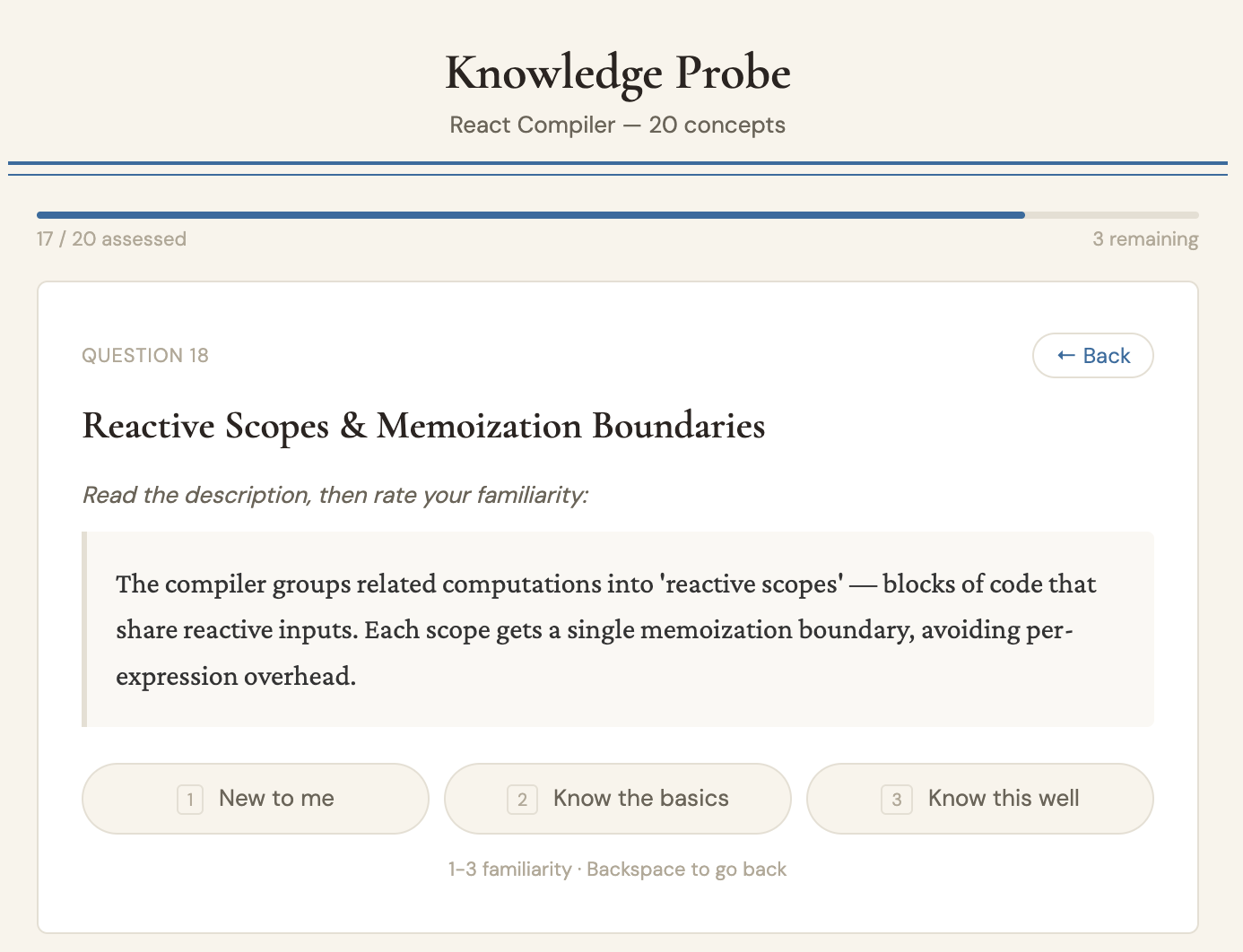
For a reading app I'm building (Petrarca — a sort of knowledge-aware read-later tool), I needed a way to quickly figure out what someone already knows about a topic. The system uses Bayesian belief propagation on a knowledge graph: it asks you a handful of targeted questions about concepts in a domain, propagates your answers through prerequisite relationships, and builds a rough profile of your understanding in about four minutes. I've tested it on things like CRDT synchronization and React internals — it's surprisingly good at figuring out where your knowledge drops off.
The obvious application for PR review: before generating the walkthrough, probe the reviewer's familiarity with the relevant concepts. If you already understand how the CRDT syncing works, skip the background and focus on what's new. If you've never touched the auth layer, give deeper context there. Instead of one-size-fits-all explanations, you get explanations shaped by what you actually need to learn.
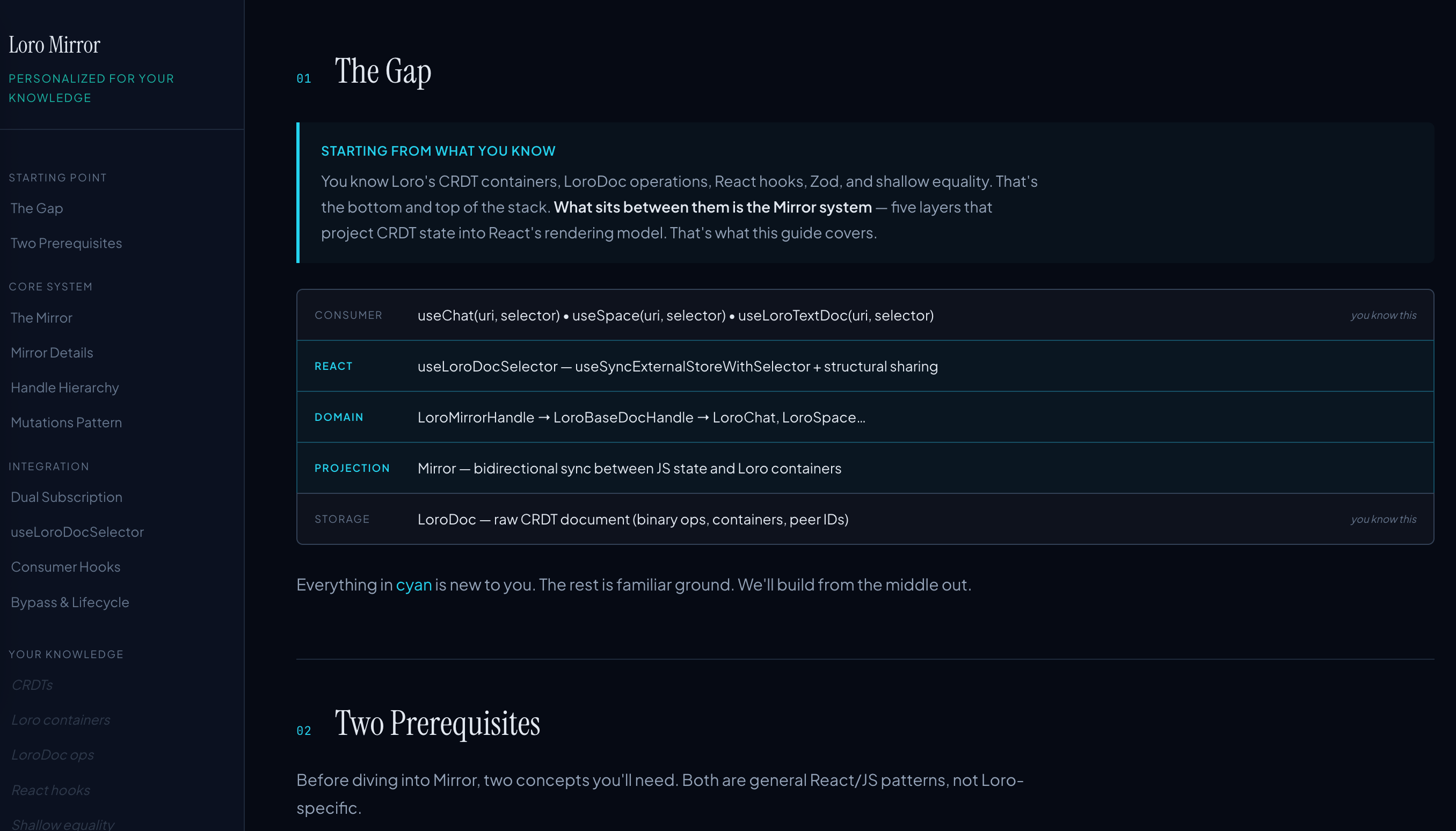
I haven't built this connection yet. But I've extracted the knowledge mapping into a standalone library, the PR tool has the architecture to support it, and... well. Writing this paragraph is probably going to make me build it this week. That's usually how this works.

What I'm left thinking about
The tool works, I use it. It makes a specific part of my job less stressful. But the thing I keep turning over is the bigger version of the same problem: we're all swimming in generated material now — AI-written code, AI-summarized reports, AI-drafted analyses — and the bottleneck has shifted from production to comprehension. The tools for producing stuff are incredible. The tools for understanding stuff are basically where they were five years ago.
I think the interesting work right now is in that gap. Not "AI does it for you" but "AI helps you actually understand what's in front of you." And ideally, helps you understand it in a way that's calibrated to what you already know and what you don't. (And helps the team understand it – some of the bigger challenges we’re working on at Tana!).
The code review tool is open-source at github.com/houshuang/ai-pr-review if you want to try it. But honestly, the tool is less interesting to me than the pattern — the way a small frustration, some research, and a couple of weeks led to something that changes how I work. I suspect a lot of people are about to have that experience in their own domains. What have you built recently? What are the frictions in your work/hobbies?