
The language learning holy grail
Comprehensible Input in a bottle
In this newsletter, I’ll talk about language learning for intermediate learners, and share a method and a tool that to me is nothing short of revolutionary.
But first, a quick update on the newsletter: I started this newsletter in February 2020, during Covid lockdown, and only wrote three posts. But I’m still very proud of them - Can we agree on the facts, Reusable media fact checking, and Learning effectively with podcasts. However, I was too ambitious, and raised the bar too high for future posts, which meant I managed to get anything more out - even though I took copious notes for a post on Wikidata for example.
Since then a lot of things have changed. I worked at Roam Research for a stint, moved to Norway, and in the past three years have been working at Tana, a really interesting project for people interested in networked thought. And I’ve kind of missed an outlet for sharing thoughts and ideas. I thought I’d reuse this newsletter, but I need to dial the ambition way down, and alongside my own interest, I’ll probably be writing a lot more about literature, theatre, history, language learning and weird rabbit holes. Feel free to try it out, and if it’s not interesting, just unsubscribe. I’ll see you around :)
Comprehensible input
Getting started in a brand new language might be frustrating at first, but also elating, because you can effectively double your vocabulary every few days, and especially when learning a language in a different script, it can feel completely magical. There are usually lots of resources available, textbooks, apps, videos etc.
The problem kicks in once you get over the initial challenge - you get your grounding, but you’re still far away from being able to read most authentic texts. It becomes really hard to track your own progress, and it can be easy to lose motivation. If you’re in the country or have easy access to other speakers, you can leverage interaction to level up the language. But if you rely on self-study, how to proceed?
For me, being able to read interesting things in the target language has always been a big motivating factor. Long before I had ever heard about Stephen Krashen and “comprehensible input”, I discussed with my other language learning friends that we need “massive input”. The typical set up of an old-school text book was a chapter with a short dialogue, a bunch of new vocabulary and grammar, some exercises… And then a new chapter - with new vocabulary and grammar. Never any chance to solidify what you’d learnt, gain fluency, feel what it’s like to be able to read the language fluently. I dreamt of a text book that after each chapter, would have a long text with narrative that didn’t introduce any new words or grammar, just let you read…

Scaffolds, ladders
Over the years, I’ve sought out various ways of bridging the gap between my knowledge, and authentic texts. The most obvious (and criminally neglected) is the parallel text. When I taught English in China, these were common in bookstores, but due to copyright they only featured 19th Century classics like “Wuthering Heights”, which was not necessarily the ideal texts for my students. Later, when I studied Russian in Moscow one summer, I came across a bilingual version of Jonathan Livingston Seagull, which was amazing. After I had gone through all the various verbs related to soaring, diving, floating etc, I could kind of read through the book. Which was a beautiful and motivating story. I looked everywhere for more - even called the publisher, but never found any of the other books in the series.
I’ve never understood why this mode of publishing isn’t more common, since it’s so obviously incredibly useful. The ancients knew – there are many old manuscripts with bilingual glosses or languages side by side, and in classics publishing, it’s extremely common to have Greek and Latin texts with translations on the side (see the famous Loebs).

(One of my early experiments was a website where you we aligned four versions of “A Doll’s House” in Chinese, Norwegian, Esperanto and Russian, and you could choose any two to read side-by-side. Imagine if there was a website where you could order a bilingual Harry Potter in any two languages - I want to see Serbian next to Hindi. With print-on-demand, it would be easy. Why is nobody doing this?)

(bilingual versions of Ibsen and many other texts)
In the absence of modern texts available in this format, I’ve frequently hacked it, simply by reading two versions side by side – often one in paper, and one on Kindle. I’ve read several Russian and Greek books like this, and found it extremely helpful, if cumbersome. It provides a lot of freedom – you can start by trying to decipher a single sentence with the help of the translation, to reading an entire paragraph and checking that you got everything – to even pre-reading a chapter in a language you know well, and seeing how much that helps you with the target language.
There are of course other tools available, some digital – browser plugins that automatically look up words for you and add it to spaced reptition etc. And some nicely designed readers, with difficult words in footnotes. But while these are common for ancient languages, they can be surprisingly hard to find for modern languages outside of the most taught.
(I have a beautiful ancient Greek version of the New Testament, in a “Reader’s Edition” by Tyndale – the most frequent words are all listed in the back, and all other words, as well as surprising conjugations, are in the footnotes. Why can’t I get a Goethe’s Faust, or “Les Miserables” or any other great text in this format?)
Spaced repetition - a new take
I’ve known about spaced repetition (using a tool like Anki to test yourself on a set of cards, which optimizes the “spacing” between each card based on your learning rate) for a long time, but I could never motivate myself to use it. Michael Nielsen’s work on memory systems for learning complex concepts was incredibly inspiring to me, and I’ve done a number of experiments with spaced repetition embedded in note taking tools, “spaced attention” etc.
There have been several issues for me with using spaced repetition for language learning. One is the input problem – how do you get content in? Manually entering words is tedious. You could use an integrated reader or a browser plugin that lets you easily add words, but that requires set up and maintenance (and reading a lot on screen). You can also use pre-made decks but that is usually a bad idea.
Then there is the boredom. But most importantly, I often end up with words that just won’t stick… I look at a Greek word, and have no idea. I flip the card - ah, it means “resource”. The next day, I see the next card… Still don’t remember. Flip the card. “Resource”. Same thing next day. Doesn’t feel productive or fun at all.
One way around it, which I discovered when experimenting with spaced reptition for more complex concepts, is that when I don’t remember something, it’s because it doesn’t have enough detail. Instead of simplifying something down, I need to add detail. For researchers, that might mean finding a picture, a paper they’ve written, some backstory. For a word, that could mean generating etymologies, example sentences etc. And of course, we now have an amazing tool for that:LLMs. After all, if it’s one thing large language models are good at, it’s language.
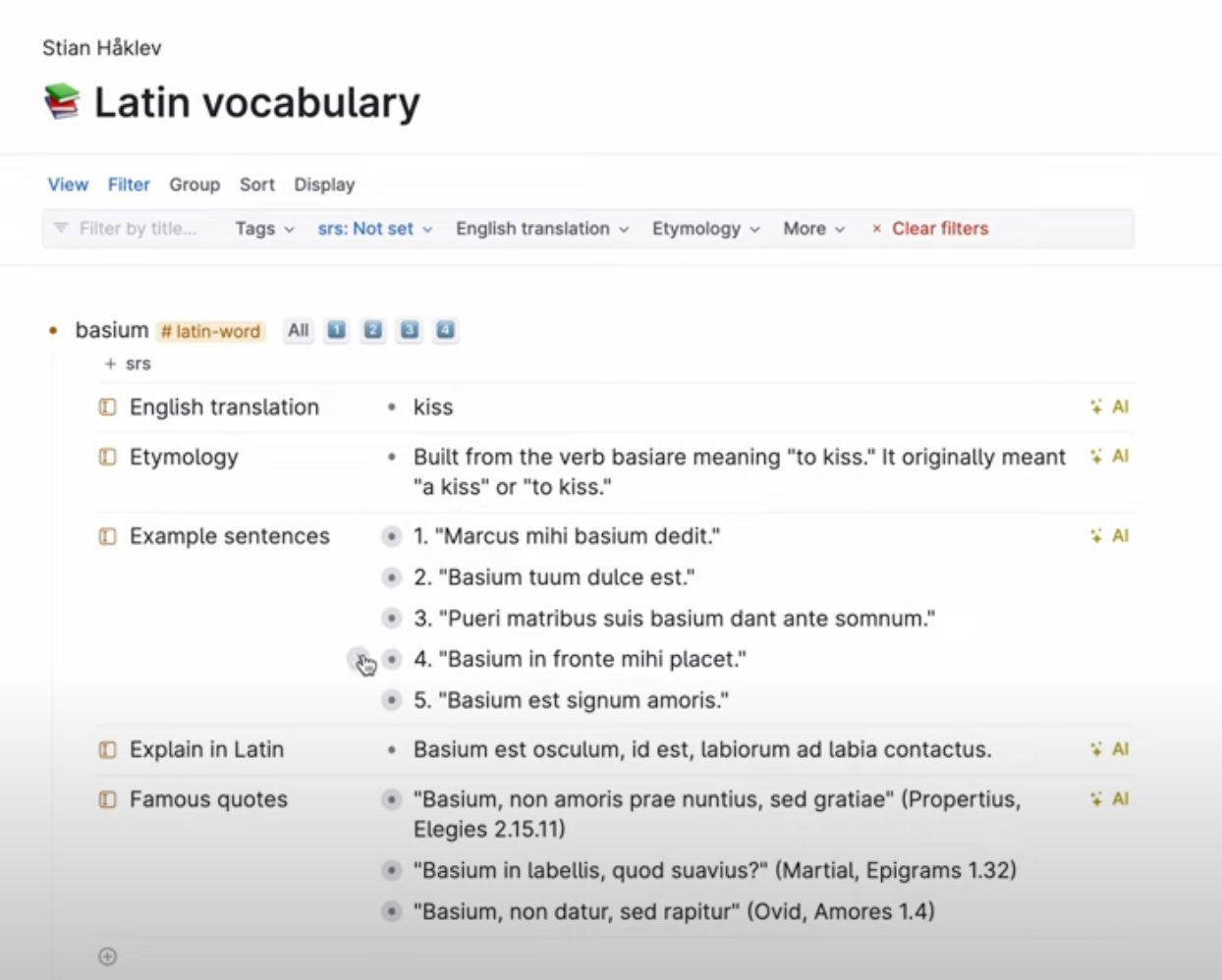
I did some experiments in Tana with automatically generating a lot of AI content for relevant Latin words, and it worked well, but at the time, Tana didn’t have a mobile app, and I realized I really need to be able to do my repetitions on mobile.
The Anki deck that changed everything (didn’t know Anki could do that) 🎉
In 2025, I had a loose plan to read the New Testament in ancient Greek. I’ve been learning Greek on and off for the last few years, and felt like I needed a consistent project to push forwards. As mentioned above, I do have a nice reader’s edition of the bible with all the vocabulary, but having to constantly check footnotes and interpret every sentences is tedious. Then I came across a brilliant Anki deck!

This deck contains the entire new testament, each card is a verse, not a single word. And each card also contains enough metadata and javascript to enable you to look up any word in the text just by clicking on it.
The cards are sequenced and will be “released” in the order they appear in the text. So with the default setting, you will see 20 new cards per day, and slowly “read” through the Bible that way (meaning it will take about 400 days to complete). But of course, cards return, some quickly because they are hard, some after a longer time, because they were easy. So when you see a card you never know exactly where it’s from (but it’s definitively from the part of the bible you’ve already read through).
My experience with this was amazing. There were lot’s of new words, but because I saw an entire verse at the same time, it was much faster to remember them, and doing reps felt interesting because I was actually spending my time reading interesting texts, not just looking at single words. With a new complex card, I might flip it right away, read the English translation, and then slowly work out the Greek, checking some of the individual words etc. With a repetition, I might recognize it and all the words immediately. Or maybe I recognize the verse and can read most of it, but don’t remember one word. I will mark it as difficult, but I still feel a sense of achievement.
But the most amazing thing is what happens next. I used this maybe 20 minutes a day (in small chunks) during a week. In the weekend, I got up early, made a fire, sat down, and opened the Tyndale’s Bible. This was the first time I was seeing the entire text as a continuous unit. And I felt like I could read it almost fluently, effortlessly – being able to focus on the plot, the language, the implications. I was reading the New Testament in Greek. Actually reading!

I couldn’t think of anything more rewarding or motivating. The sense of actually mastering a language and getting beyond decoding to actually reading.
But I want to do this with any language, any text
So I’ve been continuing to work on this, and I’m now almost through Matthew. It’s a long project, but very enjoyable – and as a side-note, I regret not reading the bible sooner. I’ve heard my whole life how many stories and idioms came from the bible, and after only finishing 60% of Matthew, I’m already seeing references, imagery, idioms everywhere, which I would have missed before.
But I’m greedy, and want more. The first thing I wanted was actually a Latin version, since I want to read the Vulgate too, and I tried to interest the guy who made the original cards into doing it (he has a Github repo, but he never responded. I’m still incredibly grateful for this great gift he gave me and everyone else).

I could have written an app to generate these cards, but I’m not sure when I would have found the time to sit down and do it. However, in these crazy futuristic times, AI can actually write entire apps for us – and it excels (for now) at these tiny greenfield projects that fill a very specific need. So far, Replit is the best that I’ve found, and after just a few back-and-forths, and not a single line of code written by me, I’ve got an app that can generate these kinds of cards for any text, and any language! Glossarium. (You can also remix it on Replit yourself).
It can probably be tweaked further, but for now it works great for Latin Vulgate, and I’ve started reading old Norse sagas with it! The prompt might need to be tweaked for a language like Chinese, and the way it divides the cards was not ideal when I tried with the Metamorphoses (a single line is a bit too little context, I’d like a few lines on each card), but these are all things that can be tweaked.
(You’ll also need to add a new fields setup to Anki with Front/Back/Glosses, and a card with some custom styling).

When to use
I am going to be experimenting more with this, with different kinds of texts, languages etc, but so far, my intuition tells me that this will work best for a language where you know the basics, but want to read texts beyond your current level. It doesn’t hurt if the text is something you are really interested in, and where you would appreciate the opportunity to read it multiple times, commit parts of it to memory etc. (Feel free to be ambitious – choose a literary masterpiece, or a beautiful poem etc).
Obviously you’ll need a digital version of the text – LLMs are getting pretty good at OCRing from an image, but of course easiest if you can find an existing text. However, I also strongly recommend you have a physical copy, ideally an old beautiful book with some character. Because part of the charm of this approach is the contrast between pulling up some sentences in biblical Greek or old Norse on a black screen while you’re waiting for the bus, or in the bathroom on the one hand – and sitting down at a cozy place with a beautiful book and actually being able to read fairly fluently, on the other. That’s where the magic happens, and the motivation and joy which is so crucial.

επίλογος (epiloge)
I took a lot of words to tell something that at its core is incredibly simple. But if you got all the way here, please try it out!
One question might be whether you learn vocabulary “as well” when always seeing it in context, and you have the option of relying on your memory. I’d argue that this is completely fine – I prefer learning vocabulary in context anyway, and what this method is doing is enabling me to read a text that I could not read otherwise. And if the word only appears once in the book, maybe it’s OK that you won’t remember the word at first when you see it in the next book – but if it occurs multiple times, you’ll get lot’s of practice – and all the reading you do while reviewing, and once you can actually read the finished book, is amazing practice.
I also have ideas for improvements. Generating Anki cards is great, since Anki already has a robust mobile app etc. But sometimes I see a long paragraph and I wish I could split it right there, or I see a word and I’d like to ask it for a better definition. I’m also thinking about the bigger picture of “incremental reading”. Maybe I’ll experiment with building a full custom app at some point. But for now, I’ve got a lot of texts to read that very previously out of reach…
I’d love to hear how it goes. Just reply to this email to leave a comment (in any language :)). 下次见!καλή μάθησις!
This is a very cool concept!
Looks like when I open the link to Glossarium, I get a page saying “not found” unfortunately.